Cluster analysis is one of the main and most important tasks of a data mining process. There are many ways to perform the clustering of the data based on several algorithms.
Since K-Means clustering is one of the mostly used algortithms, we’ve decided to write about it and developed a rich resource strictly about this specific clustering process.
This is a very hot and extense topic, so we’ve tried to consolidate all the information in an simple and easy to read article, providing a begginners’ approach to the subject.
So, let’s learn more about this process to partition data!
What is K-Means Clustering?
Basically, it is an unsupervised learning algorithm with several data analysis applications, widely used for data mining and machine learning purposes. The main goal is to classify data into groups of information.
And how is this done?
Consists on the separation of all information observations of a specific dataset into k different clusters which aggregate each one of the data entries. For this are defined k center points, one for each cluster, called centroids. Each piece of data is connected to the partition with the nearest mean from that point, that is, the neareast centroid.
As a result of this operation we’ll get k sets of data entries, each one related with one specific centroid. Within these sets, the distance to the respective centroid is minimized.
There are several variations and implementations of this clustering algorithm. However, in this article, our focus is the original method.
Algorithm
The process to achieve the result sets of classified data is quite simple. It basically consists on several iterations of a specific process, designed to get a optimal minimum solution for all data points.
Let’s look this process in detail.
First, we need to establish a fuction of what we want to minimize, in our case the distance between every data point and the correspondent centroid.
So, what we want is:
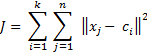
With this function well defined, we can split the process in several steps, in order to achieve the wanted result. Our starting point is a large set of data entries and a k defining the number of centers.
1 – The first step is to choose randomly k of our points as partition centers.
2 – Next, we compute the distance between every data point on the set and those centers and store that information.
3 – Supported by the last step calculations, we assign each point to the nearest cluster center. This is, we get the minimum distance calculated for each point, and we add that point to the specific partion set.
4 – Update de cluster center positions by using the following formula:

5 – If the cluster centers change, repeat the process from 2. Otherwise you have succesfully computed the k means clustering algorithm and got the partition’s members and centroids.
The achieved result is the minimum configuration for the selected start points. It is possible that this output isn’t the optimal minimum of the selected set of data, but instead a local minimum of the fuction. To mitigate this problem, we can run process more than one time in order to get the optimal solution.
It is important for you to know that there are some variations of the initial center choice method. Depending on the problem you want to solve, some initial processes might benefit your implementations.
Advantages
This clustering methodology which we described earlier, has some benefits comparing to others. The most important ones are:
- Lots of Applications – It has several live world implementations on many different subjects. We talk about the more relevant later in this article.
- Fast – Achieves the final result of its iterations in a fast way due to the simplicity of the algorithm.
- Simple and reliable – The process is farily simple and always terminates, solving the problem with a solution set even for large data sets of information.
- Efficient – This method presents a good solution with relative low computational complexity for the clustering problem.
- Good Solutions – Provides the best result set specifically when data points are fairly separated.
Disadvantages
However this implementation has some problems which need to be addressed. We provide you a list of the major ones:
- No Categorical Data – One of the bigger problems of k-means clustering is taht ir can’t be used on data entries that can’t simulate a mean fuction.
- Set Number of Clusters – In this algorithm the number of partitions must be pre-defined. If this number is badly set, the implementation and results will suffer a lot. Therefore you should use techniques to estimate the number of clusters like in this article.
- Result Set – As we explained before, the result set of this process might not be optimal.
- Initialization Method – Depending oh the chosen initialization process, the results will differ.
Example
Sometimes, the best way to understand a process is the study of some examples of its implementation. Regarding that, we developed a small simulation tool that show graphically every step of k means clustering, providing you a live example of it.
This simulation is applied to our implementation of the algorithm, which we freely share with you!
As you will see in the next video, our initial setup consists on 60 points and 5 clusters. The video shows the algorithm state with 5 seconds of interval between every step, to ensure you can follow every iteration of it.
Applications
This data aggregation methodology has several real world applications that use the benefits and results of k-means clustering on data analysis subjects.
The obvious utilization usecase is data set analysis within the subject of clustering and information representation. The solutions provided by this method are extremely usefull to aid on thos kind of processes referred above.
Another very important application is for vector quantization calculations. The division of large points of data into clusters provides the hability to perform data compression and to process signal data.
A very interesting application of this clustering mechanism is on machine learning. It can be used on unsupervised or semi supervised learning mechanisms to provide good data learning features. There is also a strong relation between this method and other learning algorithms.